Bookmark server
 In my last post, I explained how SQL Server can use an index to efficiently locate rows that qualify for a predicate. When deciding whether to use an index, SQL Server considers several factors. These factors include checking whether the index covers all of the columns that the query references (for the table in question).
In my last post, I explained how SQL Server can use an index to efficiently locate rows that qualify for a predicate. When deciding whether to use an index, SQL Server considers several factors. These factors include checking whether the index covers all of the columns that the query references (for the table in question).
What does it mean for an index to cover a column?
The heap or clustered index for a table (often called the “base table”) contains (or covers) all columns in the table. Non-clustered indexes, on the other hand, contain (or cover) only a subset of the columns in the table. By limiting the set of columns stored in a non-clustered index, we can store more rows on each page. Thus, we save disk space and improve the efficiency of seeks and scans by reducing the number of I/Os and the number of pages that we touch.
Each non-clustered index covers the key columns that were specified when it was created. Also, if the base table is a clustered index, each non-clustered index on this table covers the clustered index keys (often called the “clustering keys”) regardless of whether they are part of the non-clustered index’s key columns. In SQL Server 2005, we can also add additional non-key columns to a non-clustered index using the “include” clause of the create index statement.
For example, given this schema:
createtable T_heap (a int, b int, c int, d int, e int)
createindex T_heap_a on T_heap (a)
createindex T_heap_bc on T_heap (b, c)
createindex T_heap_d on T_heap (d) include (e)
createtable T_clu (a int, b int, c int, d int, e int)
createunique clustered index T_clu_a on T_clu (a)
createindex T_clu_b on T_clu (b)
createindex T_clu_ac on T_clu (a, c)
createindex T_clu_d on T_clu (d) include (e)
The covered columns for each index are:
|
Index |
Covered Columns |
|
T_heap_a |
|
|
T_heap_bc |
b, c |
|
T_heap_d |
d, e |
|
T_clu_a |
a, b, c, d, e |
|
T_clu_b |
a, b |
|
T_clu_ac |
a, c |
|
T_clu_d |
a, d, e |
Note that order is not relevant for covered columns.
How does this relate to index seeks and bookmark lookups?
Consider this query (using the above schema):
select e from T_clu where b = 2
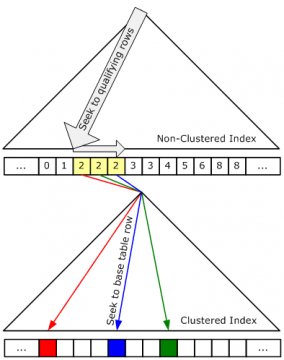
At first glance, this query looks like a perfect candidate for an index seek using the non-clustered index on column b (T_clu_b) with the seek predicate “b = 2”. However, this index does not cover column e so a seek or scan of this index cannot return the value of column e. The solution is simple. For each row that we fetch from the non-clustered index, we can lookup the value of column e in the clustered index. We call this operation a “bookmark lookup.” A “bookmark” is a pointer to the row in the heap or clustered index. We store the bookmark for each row in the non-clustered index precisely so that we can always navigate from the non-clustered index to the corresponding row in the base table.
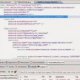
The following figure illustrates a bookmark lookup:
Showplan Samples
In SQL Server 2000, we implement bookmark lookup using a dedicated iterator whether the base table is a clustered index or heap:
|–Bookmark Lookup(BOOKMARK:([Bmk1000]), OBJECT:([T_clu]))
|–Index Seek(OBJECT:([T_clu].[T_clu_b]), SEEK:([T_clu].[b]=2) ORDERED FORWARD)
In SQL Server 2005, we use a regular clustered index seek if the base table is a clustered index or a RID (record id) lookup if the base table is a heap:
|–Nested Loops(Inner Join, OUTER REFERENCES:([T_clu].[a]))
|–Index Seek(OBJECT:([T_clu].[T_clu_b]), SEEK:([tempdb].[dbo].[T_clu].[b]=(2)) ORDERED FORWARD)
|–Clustered Index Seek(OBJECT:([T_clu].[T_clu_a]), SEEK:([T_clu].[a]= [T_clu].[a]) LOOKUP ORDERED FORWARD)
|–Nested Loops(Inner Join, OUTER REFERENCES:([Bmk1000]))
|–Index Seek(OBJECT:([T_heap].[T_heap_a]), SEEK:([T_heap].[a]=(2)) ORDERED FORWARD)
|–RID Lookup(OBJECT:([T_heap]), SEEK:([Bmk1000]=[Bmk1000]) LOOKUP ORDERED FORWARD)
You can tell that the clustered index seek is a bookmark lookup by the LOOKUP keyword in text showplan or by the attribute Lookup=“1” in XML showplan. I will explain the behavior of the nested loops join in a future post. The loop join and clustered index seek (or RID lookup) perform the same operation as the bookmark lookup in SQL Server 2000.
Share this article
Related Posts

Latest Posts